ADMON DE BASES DE DATOS
UNIDAD V
V. SEGURIDAD.
Seguridad de los datos: es la protección de la base de datos de uso mal intencionado o no autorizado.
Esta se encarga de limitar o restringir a los usuarios a realizar solo las operaciones permitidas.
Respaldo y Recuperación.
Los SGBD deben proporcionan instrumentos para evitar o remediar fallos.
Sistema de recuperación: Consiste en restaurar la BD a un estado que se sepa correcto, tras cualquier fallo que la haya dejado en un estado incorrecto o al menos sospechoso.
El objetivo de este servicio es evaluar la situación particular de cada base de datos, y proponer el mejor esquema de respaldo que garantice la mayor disponibilidad y la menor pérdida de información ante un desastre.
Recuperación.
Un sistema de recuperación consiste en restaurar la BD a un estado que se sepa correcto, tras cualquier fallo que la haya dejado en un estado incorrecto.
Recuperación de BD: “devolver la BD a un estado consistente” La recuperabilidad significa que, si se da algún error en los dato el DBA (Administrador de base de datos) puede traer de vuelta la base de datos al tiempo y estado en que se encontraba en estado consistente antes de que el daño se causara.
___________________________________________HASTA AQUI LLEGUE HOY
Las actividades de recuperación incluyen el hacer respaldos de la base de datos y almacenar esos respaldos de manera que se minimice el riesgo de daño ó pérdida de los mismos, tales como hacer diversas copias en medios de almacenamiento removibles y almacenarlos fuera del área en antelación a un desastre anticipado. La recuperación es una de las tareas más importantes de los DBA’s.
La recuperabilidad, frecuentemente denominada “recuperación de desastres”, tiene dos formas primarias. La primera son los respaldos y después las pruebas de recuperación. La recuperación de las bases de datos consiste en información y estampas de tiempo junto con bitácoras los cuales se cambian de manera tal que sean consistentes en un momento y fecha en particular. Es posible hacer respaldos de la base de datos que no incluyan las estampas de tiempo y las bitácoras, la diferencia reside en que el DBA debe sacar de línea la base de datos en caso de llevar a cabo una recuperación.
Las pruebas de recuperación consisten en la restauración de los datos, después se aplican las bitácoras a esos datos para restaurar la base de datos y llevarla a un estado consistente en un tiempo y momento determinados. Alternativamente se puede restaurar una base de datos que se encuentra fuera de línea sustituyendo con una copia de la base de datos.
Si el DBA (o el administrador) intentan implementar un plan de recuperación de bases de datos sin pruebas de recuperación, no existe la certeza de que los respaldos sean del todo válidos. En la práctica, los respaldos de la mayoría de los RDBMSs son raramente válidos si no se hacen pruebas exhaustivas que aseguren que no ha habido errores humanos ó bugs que pudieran haber corrompido los respaldos.
Respaldo.
Es la obtención de una copia de los datos en otro medio magnético, de tal modo que a partir de dicha copia es posible restaurar el sistema al momento de haber realizado el respaldo. Por lo tanto, los respaldos deben hacerse con regularidad, con la frecuencia preestablecida y de la manera indicada, a efectos de hacerlos correctamente.
Es fundamental hacer bien los respaldos. De nada sirven respaldos mal hechos (por ejemplo incompletos). En realidad, es peor disponer de respaldos no confiables que carecer totalmente de ellos. Suele ocurrir que la realización de respaldos es relegada a un plano secundario.
Existen varias maneras de respaldar base de datos MySQL, en este post únicamente mostraré una manera de hacerlo utilizando mysqldump() y PHP. Básicamente lo que se realiza es un respaldo de todas las bases de datos, por lo que el script debe ejecutarse como un usuario que tenga permisos sobre todas las bases. Adicionalmente se mantiene en disco las últimas 3 copias de los respaldos.
1. $backupFile”;
8.
9. exec($command, $salida);
10.
11. // Mantiene los ultimos 3 backups
12. $days=3;
13. $archivos = scandir(“./”);
14. foreach ($archivos as $key => $val)
15. {
16. if(substr($val,-2) != “gz”)
17. unset($archivos[$key]);
18. }
19.
20. $i=count($archivos);
21. foreach ($archivos as $key => $val)
22. {
23. if($i
Para sacar un respaldo a tu base de datos usas el mysqldump:
Código PHP:
//
shell> mysqldump -u usuario [-p] nombreBase > respaldoBase.sql
//
shell> mysqldump -u usuario [-p] nombreBase > /directorio/donde/guardas/respaldoBase.sql
Respaldar la Base de datos MySQL
Hay ocasiones donde es necesario tener el “código” de nuestra base de datos, ya sea para hacer un respaldo , para migrar la BD a otro servidor o simplemente porque se nos da la gana. Para esto MySQL cuenta con un comando muy bueno, el cual nos entrega un archivo con todas las tablas, relaciones y registros que se encuentran en la BD.
mysqldump -u usuario -p nombreDB > Archivo_de_salida.sql
Donde el usuario hay que reemplazarlo con nuestro nombre de usuario. Lo único que hay que considerar es que en el script no se encuentra la creación de la BD, así que antes de ingresar este archivo para crear la BD es necesario agregar las siguientes líneas al inicio del archivo:
CREATE nombre_base_de_datos;
USE nombre_base_de_datos;
5.1.1 Espejeo (Mirroring).
Mirroring SQL Server
El Mirroring (Base de Datos Espejo) proporciona una solución de alta disponibilidad de bases de datos, aumenta la seguridad y la disponibilidad, mediante la duplicidad de la base de datos. Esta tecnología está disponible a partir de la versión de SQL Server 2005 (es la evolución del log shipping presente en versiones anteriores)
En el Mirroring tenemos un servidor principal/primario que mantiene la copia activa de la base de datos (bbdd accesible). Otro servidor de espejo que mantiene una copia de la base de datos principal y aplica todas las transacciones enviadas por el Servidor Principal (en el que no se podrá acceder a la bbdd). Y un servidor testigo/arbitro que permite recuperaciones automáticas ante fallos, monitoriza el servidor principal y el de espejo para en caso de caída cambiar los roles (servidor opcional, no es obligatorio).
Existen varios tipos de mirroring:
Alta disponibilidad: Garantiza la consistencia transaccional entre el servidor principal y el servidor de espejo y ofrece Automatic Fail over mediante un servidor testigo.
Alta Protección: Garantiza la consistencia transaccional entre el servidor principal y el espejo.
Alto Rendimiento: Aplica las transacciones en el Servidor Espejo de manera asíncrona ocasionando mejoras significativas en el rendimiento del servidor principal pero no garantiza que dichas transacciones se hallan realizado de manera exitosa en el espejo.
Modo
|
Recuperación Automática
ante Fallos
|
Posible Pérdida
de Datos
|
Servidor Testigo
(Witness)
|
Transaction Safety
|
Alta Disponibilidad
(High Availability)
|
SI
|
NO
|
SI
|
ON
|
Alta Protección
(High Protection)
|
NO
|
NO
|
NO
|
ON
|
Alto Rendimiento
(High Performance)
|
NO
|
SI
|
NO
|
OFF
|
5.1.1.1 Beneficios del espejeo de Datos en un DBMS.
Las operaciones de Backup y Restore son actividades críticas y de orden crucial para cualquier organización, pues por motivos varios una base de datos puede llegar a fallar, los sistemas operativos, el hardware, crackers y hasta los mismos empleados pueden dañar la información. Es por eso que es importante definir políticas de Backup en una organización o por lo menos calendarizar la realización de copias de seguridad para estar preparado ante cualquier eventualidad. Dependiendo del gestor que se utilice y el tamaño de la base de datos, este puede ser una tarea fácil o relativamente compleja.
La creación de reflejo de la base de datos es una solución de software usada principalmente para aumentar la disponibilidad de una base de datos. La creación de reflejo se implementa en cada una de las bases de datos y sólo funciona con las que utilizan el modelo de recuperación completa. Los modelos de recuperación simple y de recuperación optimizado para cargas masivas de registros no admiten la creación de reflejo de la base de datos. Por lo tanto, todas las operaciones masivas se registran siempre por completo. La creación de reflejo de una base de datos funciona con cualquier nivel de compatibilidad con bases de datos.
La creación de reflejos de la base de datos mantiene dos copias de una sola base de datos que deben residir en diferentes instancias del GBD Generalmente, estas instancias de servidor residen en equipos de diferentes ubicaciones. Una instancia de servidor sirve la base de datos a los clientes (el servidor principal). La otra instancia actúa como un servidor en estado de espera activa o semiactiva (el servidor reflejado), en función de la configuración y del estado de la sesión de creación de reflejo. Cuando una sesión de creación de reflejo de la base de datos está sincronizada, la creación de reflejo de la base de datos proporciona un servidor en espera activa que admite la conmutación por error rápida sin que se produzca ninguna pérdida de datos derivada de las transacciones confirmadas. Cuando la sesión no está sincronizada, el servidor reflejado suele estar disponible como servidor en espera activa (con posible pérdida de datos).
La creación de reflejo de la base de datos es una estrategia sencilla que ofrece las siguientes ventajas:
Aumenta la protección de los datos. La creación de reflejo de la base de datos proporciona una redundancia completa o casi completa de los datos, en función de si el modo de funcionamiento es el de alta seguridad o el de alto rendimiento. Para obtener más información, vea "Modos de funcionamiento", más adelante en este tema.Un asociado de creación de reflejo de la base de datos que se ejecute en SQL Server 2008 Enterprise o en versiones posteriores intentará resolver automáticamente cierto tipo de errores que impiden la lectura de una página de datos. El socio que no puede leer una página, solicita una copia nueva al otro socio. Si la solicitud se realiza correctamente, la copia sustituirá a la página que no se puede leer, de forma que se resuelve el error en la mayoría de los casos.
Incrementa la disponibilidad de una base de datos. Si se produce un desastre en el modo de alta seguridad con conmutación automática por error, la conmutación por error pone en línea rápidamente la copia en espera de la base de datos, sin pérdida de datos. En los demás modos operativos, el administrador de bases de datos tiene la alternativa del servicio forzado (con una posible pérdida de datos) para la copia en espera de la base de datos.
Mejora la disponibilidad de la base de datos de producción durante las actualizaciones. Para minimizar el tiempo de inactividad para una base de datos reflejada, puede actualizar secuencialmente las instancias que participan en una sesión de creación de reflejo de la base de datos. Esto incurrirá en el tiempo de inactividad de sólo una conmutación por error única. Este formulario de actualización se conoce como actualización gradual.
Los dos servidores, principal y reflejado, se comunican y colaboran como asociados en una sesión de creación de reflejo de la base de datos. Los dos asociados tienen roles complementarios en la sesión: el rol principal y el rol reflejado. En cada momento, un asociado realiza el rol principal y el otro realiza el rol reflejado. Cada asociado se describe como poseedor de su rol actual. El asociado que posee el rol principal se denomina servidor principal y su copia de la base de datos es la base de datos principal actual. El asociado que posee el rol reflejado se denomina servidor reflejado y su copia de la base de datos es la base de datos reflejada actual. Cuando se implementa la creación de reflejo de la base de datos en un entorno de producción, la base de datos principal es la base de datos de producción.
La creación de reflejo de la base de datos implica rehacer cada operación de inserción, actualización y eliminación que se produce desde la base de datos principal a la base de datos reflejada tan pronto como sea posible. Para rehacer estas operaciones, se envía cada secuencia de entradas del registro de transacciones activo al servidor reflejado, que las aplica a la base de datos reflejada, en secuencia, lo más rápido posible. A diferencia de la replicación, que trabaja en el nivel lógico, la creación de reflejo de la base de datos trabaja en el nivel de registro físico. El servidor principal comprime la secuencia de entradas del registro de transacciones antes de enviarla al servidor reflejado. Esta compresión del registro se produce en todas las sesiones de creación de reflejo.
Modos de Funcionamiento
Una sesión de creación de reflejo de la base de datos se ejecuta en modo sincrónico o asincrónico. Con el funcionamiento asincrónico, las transacciones se confirman sin esperar a que el servidor reflejado escriba el registro en el disco, lo que maximiza el rendimiento. Con el funcionamiento sincrónico, una transacción se confirma en ambos asociados, pero a costa de aumentar la latencia de las transacciones.
Existen dos modos de funcionamiento de la creación de reflejo. Uno de ellos, el modo de alta seguridad, admite el funcionamiento sincrónico. En el modo de alta seguridad, cuando se inicia una sesión, el servidor reflejado sincroniza la base de datos reflejada con la base de datos principal lo más rápido posible. Una vez sincronizadas las bases de datos, una transacción se confirma en ambos asociados, pero a costa de aumentar la latencia de las transacciones.
El segundo modo de funcionamiento, el modo de alto rendimiento, se ejecuta de manera asincrónica. El servidor reflejado intenta hacer frente a las entradas de registro enviadas por el servidor principal. La base de datos reflejada podría retrasarse ligeramente en relación con la base de datos principal. No obstante, lo habitual es que dicha diferencia sea pequeña. Sin embargo, la diferencia puede ser considerable si el servidor principal soporta una gran carga de trabajo o el sistema del servidor reflejado se encuentra sobrecargado.
En el modo de alto rendimiento, en cuanto el servidor principal envía una entrada de registro al servidor reflejado, el servidor principal envía una confirmación al cliente. No espera a una confirmación del servidor reflejado. Esto significa que las transacciones se confirman sin esperar a que el servidor reflejado escriba el registro en el disco. Este funcionamiento asincrónico permite que el servidor principal se ejecute con la mínima latencia de transacciones, pero a riesgo de una pérdida potencial de datos.Todas las sesiones de creación de reflejo de la base de datos sólo admiten un servidor principal y un servidor reflejado. Esta configuración se muestra en la ilustración siguiente.

El modo de alta seguridad con conmutación automática por error requiere una tercera instancia de servidor denominada testigo. A diferencia de los dos asociados, el testigo no sirve a la base de datos. El testigo admite la conmutación automática por error al comprobar que el servidor principal se encuentre activo y en funcionamiento. El servidor reflejado inicia la conmutación automática por error sólo si éste y el testigo permanecen mutuamente conectados después de haberse desconectado del servidor principal. En la siguiente ilustración se muestra una configuración que incluye un testigo.
Seguridad de las transacciones y modos de funcionamiento.
Que el modo operativo sea asincrónico o sincrónico depende de la configuración de seguridad de las transacciones.
1.- Base de Datos Espejo(Database Mirroring)
El servidor primario como el servidor espejo mantienen una copia de la base de datos y el registro de transacciones mientras que el tercer servidor, llamado el servidor árbitro, es usado cuando es necesario dterminar cuál de los otros dos servidores puede tomar la propiedad de la base de datos. El árbitro no mantiene una copia de la base de datos. La configuración de los tres servidores de baes de datos(el primero, el espejo y árbitro) es llamado sistema Espejo (Mirroring System), y el servidor primario y espejo juntos son llamados servidores operacionales (operational Servers) o Compañeros.
Donde actuán dos servidores o más para mantener copias de la base de datos y archivo de registro de transacciones.
2.- Beneficios.
Esta característica tiene 3 modalidades que son Alto rendimiento, Alta seguridad, y Alta Disponibilidad, en este caso se habla de las 2 primeras, las cuales el levantamiento es manual.
La creación de reflejo de la base de datos es una estrategia sencilla que ofrece las siguientes ventajas:
Incrementa la disponibilidad de una base de datos. Si se produce un desastre en el modo de alta seguridad con conmutación automática por error, la conmutación por error pone en línea rápidamente la copia en espera de la base de datos, sin pérdida de datos. En los demás modos operativos, el administrador de bases de datos tiene la alternativa del servicio forzado (con una posible pérdida de datos) para la copia en espera de la base de datos. Para obtener más información, vea Conmutación de roles, más adelante en este tema.
Aumenta la protección de los datos. La creación de reflejo de la base de datos proporciona una redundancia completa o casi completa de los datos, en función de si el modo de funcionamiento es el de alta seguridad o el de alto rendimiento. Para obtener más información, vea Modos de funcionamiento, más adelante en este tema.
Un asociado de creación de reflejo de la base de datos que se ejecute en SQL Server 2008 Enterprise o en versiones posteriores intentará resolver automáticamente cierto tipo de errores que impiden la lectura de una página de datos. El socio que no puede leer una página, solicita una copia nueva al otro socio. Si la solicitud se realiza correctamente, la copia sustituirá a la página que no se puede leer, de forma que se resuelve el error en la mayoría de los casos. Para obtener más información, vea Reparación de página automática (grupos de disponibilidad/creación de reflejo de base de datos).
Mejora la disponibilidad de la base de datos de producción durante las actualizaciones. Para minimizar el tiempo de inactividad para una base de datos reflejada, puede actualizar secuencialmente las instancias de SQL Server que hospedan los asociados de creación de reflejo de la base de datos. Esto incurrirá en el tiempo de inactividad de solo una conmutación por error única. Esta forma de actualización se denomina actualización gradual. Para obtener más información, vea Instalar un Service Pack en un sistema con un tiempo de inactividad mínimo para bases de datos reflejadas.
5.1.1.2 Activación de un Espejeo en un DBMS.
1. Asegúrese de que las versiones de MySQL instalado en el maestro y en el esclavo son compatibles, debe usar la versión más reciente de MySQL en maestro y servidor. Por favor no reportar bugs hasta que ha verificado que el problema está presente en la última versión de MySQL.
2. Prepare una cuenta en el maestro que pueda usar el esclavo para conectar. Este cuenta debe tener el privilegio REPLICATION SLAVE . Si la cuenta se usa sólo para replicación (lo que se recomienda), no necesita dar ningún privilegio adicional. (Para información sobre preparar cuentas de usuarios y privilegios.
Suponga que su dominio es mydomain.com y que quiere crear una cuenta con un nombre de usuario de replique puedan usar los esclavos para acceder al maestro desde cualquier equipo en su dominio usando una contraseña de slavepass. Para crear la cuenta, use el comando GRANT:
mysql> GRANT REPLICATION SLAVE ON *.*
-> TO 'repl'@'%.mydomain.com' IDENTIFIED BY 'slavepass';
Si quiere usar los comandos LOAD TABLE FROM MASTER o LOAD DATA FROM MASTER desde el servidor esclavo, necesita dar a esta cuenta privilegios adicionales:
▪ De a la cuenta el privilegio global SUPER y RELOAD .
▪ De el privilegio SELECT para todas las tablas que quiere cargar. Cualquier tabla maestra desde la que la cuenta no puede hacer un SELECT se ignoran por LOAD DATA FROM MASTER.
Si usa sólo tablas MyISAM, vuelque todas las tablas y bloquee los comandos de escritura ejecutando un comando FLUSH TABLES WITH READ LOCK :
mysql> FLUSH TABLES WITH READ LOCK;
Deje el cliente en ejecución desde el que lanza el comando FLUSH TABLES para que pueda leer los efectos del bloqueo. (Si sale del cliente, el bloqueo se libera.) Luego tome una muestra de los datos de su servidor maestro.
La forma más fácil de crear una muestra es usar un programa de archivo para crear una copia de seguidad binaria de las bases de datos en su directorio de datos del maestro. Por ejemplo. use tar en Unix, oPowerArchiver, WinRAR, WinZip, o cualquier software similar en Windos. Para usar tar para crear un archivo que incluya todas las bases de datos, cambie la localización en el directorio de datos del maestro, luego ejecute el comando:
shell> tar -cvf /tmp/mysql-snapshot.tar .
Si quiere que el archivo sólo incluya una base de datos llamada this_db, use este comando:
shell> tar -cvf /tmp/mysql-snapshot.tar ./this_db
Luego copie el archivo en el directorio /tmp del servidor esclavo. En esa máquina, cambie la localización al directorio de datos del esclavo, y desempaquete el fichero usando este comando:
shell> tar -xvf /tmp/mysql-snapshot.tar
Puede no querer replicar la base de datos mysql si el servidor esclavo tiene un conjunto distinto de cuentas de usuario a la existente en el maestro. En tal caso, debe excluírla del archivo. Tampoco necesita incluir ningún fichero de log en el archivo, o los ficheros master.info o relay-log.info files.
Mientras el bloqueo de FLUSH TABLES WITH READ LOCK está en efecto, lee el valor del nombre y el desplazamiento del log binario actual en el maestro:
mysql > SHOW MASTER STATUS;
+---------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+---------------+----------+--------------+------------------+
| mysql-bin.003 | 73 | test | manual,mysql |
+---------------+----------+--------------+------------------+
La columna File muestra el nombre del log, mientras que Position muestra el desplazamiento. En este ejemplo, el valor del log binario es mysql-bin.003 y el desplazamiento es 73. Guarde los valores. Los necesitará más tarde cuando inicialice el servidor. Estos representan las coordenadas de la replicación en que el esclavo debe comenzar a procesar nuevas actualizaciones del maestro.
Una vez que tiene los datos y ha guardado el nombre y desplazamiento del log, puede reanudar la actividad de escritura en el maestro:
mysql> UNLOCK TABLES;
Si está usando tablas InnoDB , debería usar la herramienta InnoDB Hot Backup. Realiza una copia consistente sin bloquear el servidor maestro, y guarda el nombre y desplazamiento del log que se corresponden a la copia para usarlo posteriormente en el esclavo. InnoDB Hot Backup es una herramienta no libre (comercial) que no está incluída en la distribución de MySQL estándar. Consulte la página web de InnoDB Hot Backup en http://www.innodb.com/manual.php para información detallada.
Sin la herramienta Hot Backup , la forma más rápida de hacer una copia binaria de los datos de las tablasInnoDB es parar el maestro y copiar los ficheros de datos InnoDB, ficheros de log, y ficheros de definición de tablas (ficheros .frm). Para guardar los nombres de ficheros actual y desplazamientos, debe ejecutar el siguiente comando antes de parar el servidor:
mysql> FLUSH TABLES WITH READ LOCK;
mysql> SHOW MASTER STATUS;
Luego guarde el nombre del log y el desplazamiento desde la salida de SHOW MASTER STATUS como se mostró antes. Tras guardar el nombre del log y el desplazamiento, pare el servidor sin bloquear las tablas para asegurarse que el servidor para con el conjunto de datos correspondiente al fichero de log correspondiente y desplazamiento:
shell> mysqladmin -u root shutdown
Una alternativa que funciona para tablas MyISAM y InnoDB es realizar un volcado SQL del maestro en lugar de una copia binaria como se describe en la discusión precedente. Para ello, puede usar mysqldump --master-data en su maestro y cargar posteriormente el fichero de volcado SQL en el esclavo. Sin embargo, esto es más lento que hacer una copia binaria.
Si el maestro se ha ejecutado previamente sin habilitar --log-bin, el nombre del log y las posiciones mostradas por SHOW MASTER STATUS o mysqldump --master-data están vacíos. En ese caso, los valores que necesita usar posteriormente cuando especifica el fichero de log del esclavo y la posición son una cadena vacía ('') y 4.
Asegúrese que la sección [mysqld] del fichero my.cnf en el maestro incluye una opción log-bin . Esta sección debe también tener la opción server-id=master_id, donde master_id debe ser un entero positivo de 1 a 2^32 - 1. Por ejemplo:
[mysqld]
log-bin=mysql-bin
server-id=1
Si estas opciones no están presentes, añádalas y reinicie el servidor. Pare el servidor que se vaya a usar como esclavo y añada lo siguiente a su fichero my.cnf :
[mysqld]
server-id=slave_id
El valor slave_id, como el valor master_id , debe ser un entero positivo de 1 a 2^32 - 1. Además, es muy importante que el ID del esclavo sea diferente del ID del maestro. Por ejemplo:
[mysqld]
server-id=2
Si está preparando varios esclavos, cada uno debe tener un valor de server-id único que difiera del maestro y de cada uno de los otros esclavos. Piense en los valores de server-id como algo similar a las direcciones IP: estos IDs identifican unívocamente cada instancia de servidor en la comunidad de replicación.
Si no especifica un server-id, se usa 1 si no ha definido un master-host, de otro modo se usa 2. Tenga en cuenta que en caso de omisión de server-id, un maestro rechaza conexiones de todos los esclavos, y un esclavo rechaza conectar a un maestro. Por lo tanto, omitir el server-id es bueno sólo para copias de seguridad con un log binario.
Si ha hecho una copia de seguridad binara de los datos del maestro, cópielo en el directorio de datos del esclavo antes de arrancar el esclavo. Asegúrese que los privilegios en los ficheros y directorios son correctos. El usuario que ejecuta el servidor MySQL debe ser capaz de leer y escribir los ficheros, como en el maestro.
Si hizo una copia de seguridad usando mysqldump, arranque primero el esclavo (consulte el siguiente paso).
Arranque el esclavo. Si ha estado replicando préviamente, arranque el esclavo con la opción --skip-slave-start para que no intente conectar inmediatamente al maestro. También puede arrancar el esclavo con la opción --log-warnings (activada por defecto en MySQL 5.0), para obtener más mensajes en el log de errores acerca de problemas (por ejemplo, problemas de red o conexiones). En MySQL 5.0, las conexiones abortadas no se loguean en el log de errores a no ser que el valor sea mayor que 1.
Si hace una copia de seguridad de los datos del maestro usando mysqldump, cargue el fichero de volcado en el esclavo:
shell> mysql -u root -p < dump_file.sql
Ejecute los siguientes comandos en el esclavo, reemplazando los valores de opciones con los valores relevantes para su sistema:
mysql> CHANGE MASTER TO
-> MASTER_HOST='master_host_name',
-> MASTER_USER='replication_user_name',
-> MASTER_PASSWORD='replication_password',
-> MASTER_LOG_FILE='recorded_log_file_name',
-> MASTER_LOG_POS=recorded_log_position;
La siguiente tabla muestra la longitud máxima para las opciones de cadenas de caracteres:
MASTER_HOST
|
60
|
MASTER_USER
|
16
|
MASTER_PASSWORD
|
32
|
MASTER_LOG_FILE
|
255
|
Arranque el flujo esclavo:
mysql> START SLAVE;
Una vez realizado este procedimiento, el esclavo debe conectar con el maestro y atrapar cualquier actualización que haya ocurrido desde que se obtuvieron los datos. Si ha olvidado asignar un valor para server-id en el esclavo, obtiene el siguiente error en el log de errores:
4.- Ejemplos de creación de espacios de disco con espejo.
Se necesitará el programa R-Drive Image.
Ejecutar el programa R-Drive Image desde la ubicación en la que esté instalado.
Hacer click en el botón “Crear imagen”, que se localiza en la sección superior de la ventana principal del programa.
Seleccionar la unidad que se quiere configurar como espejo de la lista de unidades disponibles y presionar el botón “siguiente”.
Selecciona un destino para el espejo nuevo en la ventaja de navegación y haz clic en el botón "Siguiente". Éste puede colocarse en cualquier medio, como un CD, DVD u otro disco duro, dependiendo del tamaño que elijas para hacerlo.
Presiona nuevamente el botón "Siguiente" de la página "Modo de imagen" y deja marcadas las opciones por defecto. Estas opciones son para usuarios avanzados que quieren crear espejos especializados en arreglos RAID o servidores NAS.
Si lo deseas, introduce una contraseña para el espejo nuevo y haz clic en el botón "Siguiente".
Presiona el botón "Iniciar" para comenzar a crear el espejo del disco duro. Este proceso tomará desde minutos a varias horas dependiendo de la velocidad y cantidad de información del disco duro que se esté configurando. Una ventana de diálogo aparecerá para informarte cuando el proceso haya sido completado exitosamente.
5.1.1.3 Creación de Espacios de Disco con Espejo.
Espejeo
¿Qué es Espejeo?
Se conoce como copia espejo (en inglés data mirroring) al procedimiento de protección de datos y de acceso a los mismos en los equipos informáticos implementado en la tecnología de RAID1. Consiste en la idea básica de tener dos discos duros conectados. Uno es el principal y en el segundo se guarda la copia exacta del principal, almacenando cualquier cambio que se haga en tiempo real en las particiones, directorios, etc, creando imágenes exactas, etc.
De esta forma se consigue tener 2 discos duros idénticos y que permiten, si todo está bien configurado, que ante el fallo del disco principal, el secundario tome el relevo, impidiendo la caída del sistema y la pérdida de los datos almacenados.
En el "mirroring" en una base de datos tenemos un servidor principal/primario que mantiene la copia activa de la base de datos (BD accesible). Otro servidor de espejo que mantiene una copia de la base de datos principal y aplica todas las transacciones enviadas por el Servidor Principal (en el que no se podrá acceder a la BD). Y un servidor testigo/arbitro que permite recuperaciones automáticas ante fallos, monitoriza el servidor principal y el de espejo para en caso de caída cambiar los roles (servidor opcional, no es obligatorio).
Beneficios del Espejeo.
Además de proporcionar una copia adicional de los datos con el fin de redundancia en caso de fallo de hardware, la duplicación de disco puede permitir que cada disco se acceda por separado para los propósitos de lectura. En determinadas circunstancias esto puede mejorar significativamente el rendimiento ya que el sistema puede elegir para cada lectura que disco puede buscar más rápidamente a los datos requeridos. Esto es especialmente importante cuando hay varias tareas que compiten por los datos en el mismo disco, y el "trashing" (donde el cambio entre tareas ocupa más tiempo que la tarea en sí) se puede reducir. Esta es una consideración importante en las configuraciones de hardware que frecuentemente tienen acceso a los datos en el disco.
En algunas implementaciones, el disco reflejado se puede dividir fuera y se utiliza para la copia de seguridad de datos, permitiendo que el primer disco para permanecer activos. Sin embargo, la fusión de los dos discos se puede requerir un período de sincronización en su caso escribir la actividad I/O ha ocurrido con el disco duplicado.
Activación de Espejeo en un DBMS.
(Mostrar un ejemplo de cómo activar el "mirroring" en SQL Server).
Creación de Espacios de Disco con Espejo.
Una vez preparados los discos, para crear el RAID, y si hemos seguido la misma estructura de mi ejemplo, usaremos las siguientes órdenes, suponiendo que los discos nos los ha identificado como sda, sdb, sdc y sdd:
mdadm --create --level=raid1 --raid-devices=2 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
mdadm --create --level=raid5 --raid-devices=4 /dev/sda3 /dev/sdb3 /dev/sdc3 /dev/sdd3
La primera orden nos creará un RAID de tipo RAID1 con sólo 2 componentes activos, empleando para ello la primera partición de cada disco. Como le indicamos menos dispositivos de raid (2) que dispositivos físicos, lo que hace es poner los otros dos como spares.
La segunda orden nos creará un RAID5 con la tercera partición de todos los discos indicados. En este caso, el parámetro --raid-devices=4 es superfluo y se podría omitir, ya que si no decimos nada sobreentiende que queremos usar todos los discos.
Recomendaciones.
Use una copia de seguridad completa muy reciente o una copia de seguridad diferencial reciente de la base de datos principal.
Si se programa un trabajo de copia de seguridad de registros para que se ejecute muy a menudo en la base de datos principal, puede que sea necesario deshabilitar el trabajo de copia de seguridad hasta que se haya iniciado la creación de reflejo.
Si es posible, la ruta de acceso (incluida la letra de unidad) de la base de datos reflejada debería ser idéntica a la de la base de datos principal.
Si las rutas de acceso de archivo deben ser diferentes (por ejemplo, si la base de datos principal se encuentra en la unidad 'F:' pero el sistema reflejado no tiene unidad F:), se debe incluir la opción MOVE en RESTORE STATEMENT.
5.1.2 Replica (Replication).
¿Qué es?
La replicación es un mecanismo utilizado para propagar y diseminar datos en un ambiente distribuido, con el objetivo de tener mejor performance y confiabilidad, mediante la reducción de dependencia de un sistema de base de datos centralizado.
La réplica proporciona una manera rápida y confiable de diseminar la información corporativa entre múltiples localizaciones en un ambiente de negocio distribuido, permitiendo distribuir la información de manera confiable.
5.1.2.1 Beneficios de la Réplica de Datos en un DBMS.
Beneficios
Con la replicación se pueden llegar a obtener dos mejoras importantes:
Por un lado, se garantiza que el servicio ofrecido por la aplicación, no se vea interrumpido en caso de que se dé un fallo en alguna de las réplicas. Además, el tiempo necesario para restablecer el servicio en la aplicación podría llegar a ser grande en algunos tipos de fallo.
Por otra parte, la capacidad de servicio se ve incrementada cuando las peticiones efectuadas por los clientes únicamente implican consultas.
Ejemplo de una replicación
Aqui un link de un video que muestra como hacer una replicación en MySQL:
https://www.youtube.com/watch?feature=player_embedded&v=o3XP6HROljE
5.1.3 Métodos de Respaldo de un DBMS.
La clave de una administración de bases de datos segura es realizar copias de respaldo regularmente. Los sucesos imprevistos pueden resultar desastrosos debido a su importancia.
Es conveniente crear un plan de respaldo y recuperación antes desastres, con el objetivo de garantizar que todos los sistemas y datos puedan estar disponibles rápidamente, en caso de un desastre natural o técnico.
TIPOS DE FALLOS
|
SOLUCIONES
|
Violación de restricciones, tipos incompatibles, etc.
Mal funcionamiento del DBMS y/o sistema operativo.
Fallos físicos como la destrucción del medio de almacenamiento.
|
|
Modelos de Recuperación.

Modelo de recuperación
|
Descripción
|
Riesgo de pérdida de trabajo
|
Recuperacion hasta un momento dado??
|
Simple
|
Sin copias de seguridad de registros.
Recupera automáticamente el espacio de registro para mantener al mínimo los requisitos de espacio, eliminando, en esencia, la necesidad de administrar el espacio del registro de transacciones.
|
Los cambios realizados después de la copia de seguridad más reciente no están protegidos. En caso de desastre, es necesario volver a realizar dichos cambios.
|
Solo se puede recuperar hasta el final de una copia de seguridad.
|
Completa
|
Requiere copias de seguridad de registros.
No se pierde trabajo si un archivo de datos se pierde o resulta dañado.
Se puede recuperar hasta cualquier momento, por ejemplo, antes del error de aplicación o usuario.
|
Normalmente ninguno.
Si el final del registro resulta dañado, se deben repetir los cambios realizados desde la última copia de seguridad de registros.
|
Se puede recuperar hasta determinado momento, siempre que las copias de seguridad se hayan completado hasta ese momento.
|
Por medio de registros de operaciones masivas
|
Requiere copias de seguridad de registros.
Complemento del modelo de recuperación completa que permite operaciones de copia masiva de alto rendimiento.
Reduce el uso del espacio de registro mediante el registro mínimo de la mayoría de las operaciones masivas.
|
Si el registro resulta dañado o se han realizado operaciones masivas desde la última copia de seguridad de registros, se pueden repetir los cambios desde esa última copia de seguridad.
En caso contrario, no se pierde el trabajo.
|
Se puede recuperar hasta el final de cualquier copia de seguridad. No admite recuperaciones a un momento dado.
|
Copias De Seguridad Completa (Recuperacion Simple):
BACKUP DATABASE nombre_base_datos TO DISK = “ < Ruta_Absoluta | Ruta_Relativa >Nombre_Archivo.bak” [WITH FORMAT] [NAME = ‘Nombre Lógico del Respaldo’]
FORMAT Y INIT sobrescriben la copia de seguridad almacenada en el medio especificado.
Restaurar Copia De Base De Datos Completa
RESTORE DATABASE NOM_BD FROM DISK = “ < Ruta_Absoluta | Ruta_Relativa >Nombre_Archivo”
[WITH RECOVERY]
Copias De Seguridad Diferencial (Recuperacion Simple).
BACKUP DATABASE NOMBRE_BASE_DATOS TO DISK = “ < Ruta_Absoluta | Ruta_Relativa >Nombre_Archivo” WITH DIFFERENTIAL [NAME = ‘Nombre Logico del Respaldo’]
Restaurar Copia De Base De Datos Diferencial.
RESTORE DATABASE NOM_BD FROM DISK = “ < Ruta_Absoluta | Ruta_Relativa >Nom_Archivo_Ultimo_Respaldo_BD” WITH NO RECOVERY
RESTORE DATABASE NOM_BD FROM DISK = “ < Ruta_Absoluta | Ruta_Relativa >Nom_Respaldo_Diferencial” WITH RECOVERY
Copias De Seguridad De Registro De Transacciones (Recuperación Completa).
El modelo de recuperación completa utiliza copias de seguridad de la base de datos y del registro de transacciones para ofrecer una protección completa en caso de error de los datos.
Si se daña uno o varios archivos de datos, la recuperación de los medios podrá restaurar todas las transacciones confirmadas.
Requiere copias de seguridad de registros.
No se pierde trabajo si un archivo de datos se pierde o resulta dañado.
Las transacciones en curso se deshacen.
Normalmente no hay pérdida de trabajo.
Este tipo de recuperación (completa) permite recuperar la base de datos hasta el momento del error o hasta un momento determinado del tiempo.
Para garantizar este grado de recuperación, todas las operaciones, incluidas las operaciones como SELECT INTO, CREATE INDEX y los datos de carga masiva se registran completamente.
BACKUP LOG NOM_BASE_DATOS TO DISK = ‘< Ruta_Absoluta | Ruta_Relativa >Nom_Respaldo_Log.trn’
BACKUP LOG NOM_BASE_DATOS TO DISK = ‘< Ruta_Absoluta | Ruta_Relativa >Nom_Respaldo_Log.trn’
WITH NO_TRUNCATE
Restaurar A Un Momento Específico.
La restauración a un momento específico siempre se realiza a partir de una copia de seguridad del registro. En cada instrucción RESTORE LOG de la secuencia de restauración, debe especificar el momento de destino o transacción en una cláusula STOPAT idéntica. Como requisito previo para la restauración a un momento específico, debe restaurar primero una copia de seguridad completa de la base de datos cuyo punto final sea anterior al momento de restauración de destino.
La copia de seguridad completa de la base de datos puede ser anterior a la copia de seguridad completa de la base de datos más reciente siempre y cuando restaure cada copia de seguridad del registro siguiente, hasta la copia de seguridad del registro que contiene el momento específico de destino, inclusive.
Sintaxis.
RESTORE LOG database_name FROM <backup_device> WITH STOPAT =time, RECOVERY…
El punto de recuperación es la última confirmación de transacción que se ha producido durante o antes del valor datetime que se especifica en time. Para recuperar únicamente las modificaciones que se han realizado antes de un momento concreto, especifique WITH STOPAT = time para cada copia de seguridad que restaure. Esto garantiza que no se pasará el momento de destino.
Por lo general, una secuencia de restauración a un momento dado implica las siguientes etapas:
Restaure la última copia de seguridad de base de datos completa y, si existe, la última copia de seguridad diferencial de base de datos sin recuperar la base de datos (RESTORE DATABASE database_name FROM backup_device WITH NORECOVERY).
Aplique cada copia de seguridad del registro de transacciones en la misma secuencia en que fueron creadas, especificando la hora a la que tiene previsto detener la restauración del registro (RESTORE DATABASE database_name FROM <backup_device> WITH STOPAT=time, RECOVERY).
5.1.3.1 Elementos y Frecuencia de Respaldo.
Dado que las aplicaciones (sistemas) tiene características inherentes para cada aplicación corresponde un método apropiado de respaldo / recuperación de datos. Preferentemente, debe ser establecido por quienes desarrollan la aplicación que son los saben cuáles datos es necesario respaldar, la mejor manera de hacerlo, etc. y como hacer la correspondiente recuperación. Hay que tener en cuenta las características propias del usuario y cuál es la instalación en que funciona el sistema. Es decir, que computadora, dónde está instalada, etc. Incluye el área física (por ejemplo: ambiente aislado, acondicionamiento térmico, nivel de ruido, etc.)
Algunos de los aspectos a considerar se presentan a continuación. La lista no es taxativa y el orden de cada aspecto no es relevante, siendo cada aspecto de propósito limitado en forma individual. Un adecuado método de respaldo / recuperación debe tener en cuenta todos los aspectos en conjunto, como ser:
|
|
Quienes los manejan.
Verificación del respaldo.
Registro.
Cuándo hacerlo
El respaldo completo del disco
Soporte físico a utilizar para el respaldo.
|
Establecer La Frecuencia De Respaldo
Normalmente cuando uno plantea que va a respaldar los datos de su PC a una persona en una compañía uno tiene que definir muy bien cuál es la información crítica para la empresa, por ejemplo la música que guarde un empleado en su PC no es crítica para las actividades de la empresa ni lo son las fotos de su última fiesta. En cambio su correo electrónico, proyectos, informes y papeles administrativos si lo suelen ser y tener un respaldo de estos es clave para el funcionamiento de la empresa en caso de cualquier eventualidad.
Normalmente la data o información que es respaldada por las empresas es:
Archivos creados por aplicaciones, como por ejemplo .doc, .odt, .xls, .mdb, .pdf, .ppt entre otros.
Archivos de correo electronic.
Directorios telefónicos y de contactos.
Favoritos de los navegadores como Firefox e Internet Explorer.
Base de datos.
Configuraciones de los equipos.
Archivos de CAD, PSD, XCF, etc.
Imágenes y Fotografías de proyectos.
Configuraciones de servicios.
Clasificación de Respaldos
Copias de Información (Backups).
Estos respaldos son sólo duplicados de archivos que se guardan en "Tape Drives" de alta capacidad. Los archivos que son respaldados pueden variar desde archivos del sistema operativo, bases de datos , hasta archivos de un usuario común. Existen varios tipos de Software que automatizan la ejecución de estos respaldos, pero el funcionamiento básico de estos paquetes depende del denominado archive bit.
Este archivo bit indica un punto de respaldo y puede existir por archivo o al nivel de "Bloque de Información" (típicamente 4096 bytes), esto dependerá tanto del software que sea utilizado para los respaldos así como el archivo que sea respaldado. Este mismo archive bit es activado en los archivos (o bloques) cada vez que estos sean modificados y es mediante este bit que se llevan acabo los tres tipos de respaldos comúnmente utilizados:
Respaldo Completo ("Full"): Guarda todos los archivos que sean especificados al tiempo de ejecutarse el respaldo. El archive bit es eliminado de todos los archivos (o bloques), indicando que todos los archivos ya han sido respaldados.
Respaldo de Incremento ("Incremental"): Cuando se lleva acabo un Respaldo de Incremento, sólo aquellos archivos que tengan el archive bit serán respaldados; estos archivos (o bloques) son los que han sido modificados después de un Respaldo Completo. Además cada Respaldo de Incremento que se lleve acabo también eliminará el archive bit de estos archivos (o bloques) respaldados.
Respaldo Diferencial ("Differential"): Este respaldo es muy similar al "Respaldo de Incremento" , la diferencia estriba en que el archive bit permanece intacto.
Frecuencia de Actualización de la Información
Hay dos puntos importantes en cuanto a la actualización de la información
Que tan frecuentemente se actualiza la información.
Si queremos guardar un histórico de la información o no.
No toda la información se actualiza con la misma frecuencia, hay información que puede durar años sin ser modificada y otra que se actualice constantemente todos los días, es importante definir qué información se actualiza y en qué momento para hacer una política de respaldo más eficiente.
La mayoría de las aplicaciones de respaldos hacen esto automáticamente fijándose en la fecha de modificación del archivo y comparándola con la que tiene en el respaldo. El otro punto es si queremos hacer un respaldo con históricos o duplicados, en este caso tenemos que indicarle al programa que no queremos que nos borre o sobrescriba ningún archivo y que vaya guardando los archivos con su respectiva fecha y con qué frecuencia queremos hacer el respaldo.
En caso de que haya información que se pueda sobre escribir o actualizar, se realiza un respaldo incremental donde sólo se actualiza lo que ha cambiado del archivo lo que mejora la eficiencia de nuestro sistema. Esto realmente va a depender del tipo de información y varía de empresa a empresa pero es algo importante que se tiene que tomar en cuenta ya que toda la información no es igual.
5.1.3.2 Comandos para Respaldo de Datos.
Respaldo y Restauración MySQL de Manera Local.
Para hacer un respaldo de una base de datos MySQL desde nuestro consola o mediante comandos shell podemos usar el comando mysqldump como lo ejemplificamos en la siguiente liga.
Comando: mysqldump -u "usuario" -p"contraseña" nombre-de-la-base-de-datos > nombre-del-respaldo.sql
NOTA: Las comillas deben omitirse tanto en el usuario como en la contraseña.
Para restaurar un respaldo de una base de datos MySQL usamos el siguiente comando.
Comando: mysql -u "usuario" -p"contraseña" nombre-de-la-base-de-datos < nombre-del-respaldo.sql
NOTA: Al igual que en el ejemplo anterior las comillas deben omitirse tanto en el usuario como en la contraseña.
Respaldo y Restauración MySQL de Manera Remota.
Para Respaldar o Restaurar una Base de datos remota usamos los mismos comandos que de manera local, con la única diferencia de agregar la opción "-h" con la cual especificaremos el nombre o dirección del host en donde se encuentra nuestra base.
Para Respaldar usamos:
Comando: mysqldump -u "usuario" -p"contraseña" -h"nombre-o-dirección-del-host" nombre-de-la-base-de-datos > nombre-del-respaldo.sql
Para restaurar usamos:
Comando: mysql -u "usuario" -p"contraseña" -h"nombre-o-dirección-del-host" nombre-de-la-base-de-datos < nombre-del-respaldo.sql
5.1.3.3 Métodos de recuperación de un DBMS
Existen diversos métodos para la restauración de una base de datos corrupta a un estado previo libre de daños. El tipo de técnica de recuperación usado en cada situación determinada depende de varios factores, incluyendo los siguientes:
La extensión del daño sufrido por la base de datos. Por ejemplo, si se encuentra que ha sido un único registro el que ha sufrido daños, la técnica de recuperación es trivial, en comparación con el procedimiento de restauración necesario después de un choque de una cabeza. El nivel de actividad de la base de datos. Las técnicas de recuperación son fáciles de implementar en bases de datos que se modifican con escasa frecuencia. Por el contrario, resulta mucho más difícil y caro el diseño de técnicas de recuperación para bases de datos que se están actualizando continuamente. En este último caso, suele tratarse también de bases de datos de gran importancia para sus usuarios, por lo que es de vital importancia que la recuperación sea rápida.
La naturaleza de la información de la base de datos. Para algunos tipos de datos, la pérdida de una pequeña cantidad de información puede no resultar particularmente crítica. En otras situaciones, tales como bases de datos financieras, no es aceptable ninguna pérdida de datos, independientemente de su cuantía. Los dos tipos de circunstancias requieren muy diferentes aproximaciones en lo que se refiere a fiabilidad y recuperación.
Copias de seguridad de la base de datos
Para poder efectuar cualquier tipo de restauración de una base de datos, es necesaria la realización de copias de seguridad (Backus) de la base de datos de forma periódica. Este proceso consiste en la escritura de una copia exacta de la base de datos en un dispositivo magnético separado del que contiene a la propia base de datos. En los sistemas más grandes, este dispositivo suele ser una cinta magnética. En los sistemas basados en microordenadores, puede tratarse de un cartucho de cinta de casete, o de uno o más discos flexibles. Habitualmente, mientras se está generando una copia de seguridad es preciso detener todas las demás actividades de la base de datos.
A menudo se realiza más de una única copia, que luego se almacenan en un lugar lejos del ordenador, y alejadas entre sí, con el fin de que si algún tipo de suceso catastrófico produjese la destrucción del ordenador, al menos una de las copias en cinta no resultase dañada por el mismo suceso. Cuando se trata de bases de datos críticas, como las que guardan información bancaria, suele guardarse al menos una copia en un lugar alejado bastantes kilómetros de la instalación del ordenador. Además, no es raro que se mantengan varias generaciones de copias, para añadir un nivel de seguridad adicional.
Un método sencillo de recuperación
El método más simple de recuperación de una base de datos es el expuesto a continuación. Periódicamente, quizá una vez cada día, se realiza una copia de seguridad de la base de datos. Comenzando a partir del momento en el que se hace cada copia, se lleva manualmente una lista física, o diario (log), de todos los cambios subsiguientes que se efectúan en la base de datos. Si la base de datos es dañada o destruida, para recuperarla es preciso seguir la secuencia de pasos siguiente:
Reparar el problema de hardware o software que causó la caída del sistema.
Restaurar la base de datos a partir de la copia de seguridad más reciente. Esto no restaura la base de datos a su estado en el instante en el que tuvo lugar el daño.
Volver a introducir manualmente en la base de datos los cambios realizados desde que se hizo la copia, usando la lista física.
Diarios de Transacciones y Restauración/Reejecución.
Una extensión de la técnica anterior consiste en el mantenimiento automático de un fichero de ordenador, que contenga una lista de los cambios hechos en la base de datos entre dos copias de seguridad consecutivas. Esta lista se conoce como diario de transacciones, y se mantiene siempre en un dispositivo físico diferente del que almacena a la propia base de datos. Habitualmente se utiliza para este propósito una unidad de cinta magnética, o una unidad de disco diferente. La razón para usar un dispositivo separado es simplemente que si la base de datos resulta dañada, la causa de dicho daño no tiene por qué afectar a los datos almacenados en un dispositivo físico diferente.
La forma de utilizar un diario de transacciones como ayuda para la restauración es idéntica a la que ya se ha descrito, excepto en la última etapa. En este caso, la restauración de las transacciones anotadas en el diario las realiza una utilidad del SGBD, que devuelve la base de datos al estado inmediatamente anterior al momento del fallo. Este proceso se conoce habitualmente como restauración/reejecución.
La clave para el uso con éxito de un diario de transacciones radica en la capacidad del SGBD para reconocer el comienzo y el final de cada transacción. Para cada transacción de la base de datos, el diario contienemarcas de “comienzo de transacción” y “final de transacción”, además de una grabación de los cambios individuales realizados en la base de datos para dicha transacción. La marca de “ final de transacción” se graba en el diario sólo después de la conclusión con éxito de la transacción.
Así, si una caída del sistema interrumpe el procesamiento de una transacción, no aparecerá ninguna marca de “final de transacción” en el diario. Cuando se realice un proceso de restauración/reejecución, sólo se restaurarán a partir del diario las transacciones completadas, y se generará un informe impreso, que indicará qué transacciones no se han completado y, por tanto, no han sido introducidas en la base de datos.
Para bases de datos extremadamente activas, la técnica de restauración/reejecución puede resultar inadecuada, ya que el reprocesamiento del diario puede llevar varias horas, durante las cuales la base de datos no puede ser usada con normalidad. Si una base de datos es muy activa, esta no disponibilidad puede revelarse intolerable, y será preciso emplear otras técnicas de restauración.
Recuperación por Retroceso
La recuperación por retroceso resulta útil en situaciones en las que el procesamiento de la base de datos se ve interrumpido, pero la base de datos en sí no resulta dañada de forma alguna. Un ejemplo de esto podría ser algún tipo de fallo que produzca una terminación anormal de la ejecución del SGBD. Las transacciones en marcha podrían ser abortadas antes de su finalización, y los registros asociados a las mismas quedarían en estados desconocidos, aunque el resto de la base de datos no se vería afectada.
La técnica de recuperación por retroceso requiere que el diario de transacciones contenga imágenes iniciales de cada registro de la base de datos que haya sufrido modificaciones desde la última copia de seguridad. Una imagen inicial es una copia de un registro tal como se encontraba inmediatamente antes de ser modificado como parte de una transacción, es decir, justo antes del inicio de dicha transacción.
El procesado de recuperación por retroceso conlleva que después de que se haya colocado nuevamente en funcionamiento el SGBD, con la base de datos correcta, tal como estaba cuando tuvo lugar la interrupción, se pase a procesar el diario de transacciones. Para cada transacción incompleta anotada en el diario se reemplaza la versión actual del registro de la base de datos por la imagen inicial correspondiente. Así, cada registro de la base de datos que ha sufrido modificaciones durante una transacción no completada es devuelto a su estado inicial, antes del comienzo de la transacción. El resultado de este proceso es la eliminación de la base de datos de todas las huellas de transacciones incompletas, es decir, las que estaban en marcha cuando tuvo lugar la caída.
Para que la recuperación por retroceso pueda funcionar, el diario de transacciones debe contener marcas de “comienzo de transacción” y de “final de transacción” para cada transacción. Cuando se realiza un proceso de recuperación, las transacciones incompletas se detectan por la ausencia de una marca de “final de transacción”.
La cantidad de esfuerzo necesaria para efectuar una recuperación por retroceso puede ser mucho menor que la que se necesita para una recuperación por restauración/reejecución. Por ejemplo, supongamos que se han grabado 1000 transacciones en un diario entre el momento en que se hizo la última copia de seguridad y el instante del fallo (un fallo que no dañe a la base de datos). Supongamos asimismo que en el instante del fallo se encuentran en marcha 5 transacciones. Con la técnica de restauración/reejecución, la base de datos debe ser restaurada a partir de la última copia, por lo que habrá que procesar 995 transacciones. Por su parte, una recuperación por retroceso parte de la base de datos tal como se encuentra, limitándose a deshacer los efectos de las 5 transacciones incompletas.
Recuperación por Adelanto.
El adelanto es otro tipo de mecanismo de recuperación, que se usa a menudo cuando una base de datos ha sido dañada y debe, por tanto, ser restaurada a partir de una copia de seguridad. Se parece a la técnica del retroceso, y comparte con ésta la ventaja de que es mucho más rápida que el método de restauración/reejecución. Requiere que el diario de transacciones contenga una imagen final de cada registro de la base de datos que ha sido modificado desde la última copia. Una imagen final es una copia de un registro, inmediatamente después de haber sido modificado como parte de una transacción, es decir, en el estado en que se encuentra al finalizar dicha transacción.
En su forma más simple, esta técnica consta de dos etapas:
Después de un fallo que produce un daño en la base de datos, se utiliza la última copia de seguridad para restaurarla.
Se procesa el diario, a partir del punto en que se efectuó la última copia de seguridad. Para cada transacción completada anotada en el diario, se sustituye la versión actual del registro de la base de datos por la imagen final correspondiente.
Esta técnica es considerablemente más rápida que la de restauración/reejecución, ya que la sustitución de un registro por su imagen final lleva mucho menos tiempo que el proceso de recreación de la base de datos completa a partir de la copia de seguridad.
Existen variaciones del método de adelanto básico, diseñadas para mejorar aún más la velocidad de la recuperación de la base de datos. Por ejemplo, el conjunto completo de imágenes finales puede ordenarse primero por número de registro. De esta forma, después sólo hace falta escribir en la base de datos la última imagen final de cada registro. Para los registros con varias modificaciones anotadas en el diario, esto puede suponer un considerable ahorro en tiempo de procesamiento.
5.1.4 Comandos Para Recuperación.
Mantenimiento y monitoreo de la Base
Actividad
|
Comando
|
Revisar el estado de las tablas
|
show table status;
|
Los procesos que están ejecutándose
|
show processlist;
|
Variables con las que se está ejecutando la instancia
|
show variables;
|
Estado actual de innodb;
|
show innodb status;
|
Respaldos.
La manera usual de hacer un respaldo es usando el comando mysqldump, que posee muchas opciones que permiten duplicar todas las base, una base en particular, una tabla, solo los datos, solo la estructura, etc.
Para obtener un respaldo completo de una base
[digital@pcproal digital]$ mysqldump --opt -u carlos -p prueba > prueba.bak
Para restaurar un respaldo completo de una base
[digital@pcproal digital]$ mysql -u carlos -p prueba < prueba.bak
Otra manera de hacer respaldos es a través del comando "Select Into" y restaurar los datos con "mysqlimport" o "load data infile".
Redo Log Files: dos o más archivos donde se registra cualquier modificación transacción al de una memoria intermedia de la BD. (Memoria intermedia)
Archivos de control: metadatos necesarios para operar en la Base de Datos, incluyendo información sobre copias de seguridad. Guían la recuperación. (Como un diccionario de datos)
Segmento Rollback: guarda las últimas sentencias realizadas sobre la BD y sabe cuándo se ha confirmado o no una transacción.
5.1.4.1 Ventajas y Desventajas de Cada Método
Servicios de Respaldo y Recuperación para Bases de Datos (BD)
Vamos a comenzar esta lectura con algunas preguntas que a medida que avance la lectura, serán respondidas:
¿Por qué debemos respaldar una BD? ¿Es posible recuperar información? ¿Cuál es la importancia de este tipo de servicios?
¿Como funcionan?
¿Son soportadas por los principales Sistemas de BD? ¿Cuál es el caso de PostgreSQL?
Es de suma importancia tener algún sistema de respaldo/recuperación de datos, pues esto permite:
Tener sistemas con cierto nivel de seguridad y estabilidad ante posibles fallos.
Poder volver a un punto seguro en el estado de la BD, debido a cambios peligrosos.
Su funcionamiento está basado en estados. En cada momento la BD se encuentra en un estado definido. Cuando se realizan operaciones de modificación, es decir:
INSERT
UPDATE
DELETE
Cambiamos su estado, llevándolo a uno nuevo.
Nota: No se considera SELECT, pues no provoca cambios. Recordemos que es una operación de selección. Al momento de realizar un respaldo, se guarda el estado en que se encuentra la BD al momento de realizar dicha operación de respaldo. Al momento de realizar la operación de recuperación, puede ser de varias formas, ya sea a través de las operaciones (en orden) que han dejado la BD en el estado actual u otras formas. La gran mayoría de Motores de BD cuentan con funciones de este tipo.
Esta función genera un archivo de texto con comandos SQL que, cuando son reintroducidos (bajo cierto contexto) al servidor, se deja a la BD en el mismo estado en el que se encontraba al momento de ejecutar este comando.
Nota: Esto ocurre siempre y cuando la BD esté vacía, es decir, en el mismo estado inicial. pg_dump guarda los comandos introducidos hasta el punto de control. El ejemplo 1 permitirá aclarar dudas.
su sintaxis es:
pg_dump dbname > archivo_salida
y se usa desde la linea de comandos. Para realizar la restauración se utiliza:
psql dbname < archivo_entrada
Donde archivo_entrada corresponde al archivo_salida de la instrucción pg_dump.
Ejemplo 1.
Supongamos que tenemos una BD llamada lecture31 y dentro de ella una única tabla llamada Numbers con atributosNumber Y Name, con datos:
1 One
2 Two
3 Three
Es decir:
CREATE DATABASE lecture31;
conectándose:
\c lecture31
CREATE TABLE Numbers(Number INTEGER, Name VARCHAR(20));
INSERT INTO Numbers VALUES (1, 'One' );
INSERT INTO Numbers VALUES (2, 'Two' );
INSERT INTO Numbers VALUES (3, 'Three' );
A través de un select:
number | name
-----------+-------
1 | One
2 | Two
3 | Three
Para realizar el respaldo, se utiliza pg_dump:
pg_dump lecture31 > resp.sql
Un posible problema a la hora de ejecutar pg_dump es:
pg_dump lecture31 > resp.sql (bash: permission denied)
Para evitar esto, es necesario considerar que el usuario de la BD debe tener permisos de escritura en la carpeta donde se alojará el archivo.
Nota: Para los usuarios locales, basta con hacer “cd” en la linea de comandos (como usuario postgres), para acceder a la carpeta de postgres. Si desea realizar pruebas desde el servidor dedicado, puede crear BDs desde su sesión y alojar los archivos de respaldo en su capeta home.
Nota: Es posible cambiar los permisos de lectura y escritura de las carpetas, dar accesos a usuarios que no son dueños de las BD. No se profundiza esto, pues escapa a los alcances de este curso.
Supongamos que se comete un error, se borra información de seguridad nacional, digamos la tupla “1, One”. Utilizando el archivo de respaldo es posible volver al estado anterior:
psql lecture31 < resp.sql
Nota: Nótese que dentro de la salida del comando aparece: ERROR: relation “numbers” already exists
Revisando la tabla a través de:
\c lecture31
SELECT * FROM Numbers;
La salida es:
number | name
-----------+-------
2 | Two
3 | Three
1 | One
2 | Two
3 | Three
Lo cual, claramente, no corresponde a la información inicial.
Antes de restaurar, es necesario recrear el contexto que tenía la BD. Específicamente usuarios que poseían ciertos objetos o permisos. Si esto no calza con la BD, original, es posible que la restauración no se realice correctamente.
En este caso el contexto inicial corresponde a una BD vacía, dentro de la cual se crea una tabla y se agregan algunos datos Se invita al lector a borrar la tabla y realizar la restauración.
Es necesario aclarar que se necesita una BD existente para hacer la restauración. Si ésta no existe, por ejemplo utilizar lecture32 en lugar de 31, el siguiente error aparecerá:
psql: FATAL: database "lecture32" does not exist
Pero ¿Qué ocurre si utilizamos el atributo number como PK?, es decir modificar sólo la linea (y seguir el resto de los pasos de la misma forma):
CREATE TABLE Numbers(Number INTEGER, Name VARCHAR(20), PRIMARY KEY (Number));
Al momento de borrar la tupla, digamos (3, ‘Three’), e intentar restaurar, dentro de la salida del comando aparece:
ERROR: relation "numbers" already exists
ERROR: duplicate key violates unique constraint "numbers_pkey"
CONTEXT: COPY numbers, line 1: "1 One"
ERROR: multiple primary keys for table "numbers" are not allowed
¿Qué ocurre si se elimina la primera tupla antes de restaurar?
Ejemplo 2.
Este ejemplo es muy similar al anterior, sólo que, en lugar de trabajar con atributos INTEGER, se trabajará con atributo serial es decir:
\c lecture31
DROP TABLE Numbers;
CREATE TABLE Numbers2(Number SERIAL, Name VARCHAR(20));
INSERT INTO Numbers2 (name) VALUES ('One' );
INSERT INTO Numbers2 (name) VALUES ('Two' );
INSERT INTO Numbers2 (name) VALUES ('Three' );
Es decir que si se hace un select, se podrá ver:
Number | name
---------- +-------
1 | One
2 | Two
3 | Three
Para poder realizar el respaldo, utilizando pg_dump:
pg_dump lecture31 > resp2.sql
Digamos que se agrega la tupla (4, ‘Four’) y borra la tupla (3, ‘Three’). Después de realizar el respaldo:
number | name
-----------+-------
1 | One
2 | Two
4 | Four
Posteriormente se realiza la restauración:
psql lecture31 < resp.sql
Nota: Nótese que en la salida, es posible ver: setval 3
Revisando la tabla a través de:
\c lecture31
SELECT * FROM Numbers2;
La salida es:
number | name
-----------+-------
1 | One
2 | Two
4 | Four
1 | One
2 | Two
3 | Three
Lo cual es un problema, pues se trabaja con valores seriales. De hecho si en este estado se agrega la tupla (4, Four) y se revisan los contenidos de la tabla, la salida es:
number | name
-----------+-------
1 | One
2 | Two
4 | Four
1 | One
2 | Two
3 | Three
4 | Four
Esto ocurre debido a que el contador serial vuelve a 3.
Ejercicio propuesto
Se deja en manos del lector ver que ocurre en caso de trabajar con atributo serial PK, es decir:
CREATE TABLE Numbers2(Number SERIAL, Name VARCHAR(20), PRIMARY KEY (number));
y luego seguir los mismos pasos, es decir agregar las tuplas (1, ‘One’), (2, ‘Two’) y (3, ‘Three’). Luego realizar un respaldo, acceder a la BD, eliminar la última tupla, agregar (4, ‘Four’), realizar la restauración, intentar agregar más tuplas (conectándose a la BD primero) y los que desee hacer el lector.
A modo de pista, si al agregar una tupla, aparece:
ERROR: duplicate key value violates unique constraint "numbers2_pkey"
Siga intentando, verá que es posible agregar más tuplas. Fíjese en el valor de la llave primaria. ¿Cuántas veces tuvo que intentar?
¿Qué ocurre si en lugar de eliminar la última tupla, se elimina la primera?
pg_dumpall
Un pequeño inconveniente con pg_dump es que sólo puede hacer respaldos de una BD a la vez. Además no respalda información acerca de roles de usuario e información por el estilo
Para realizar un respaldo de la BD y el cluster de datos, existe el comando pg_dumpall.
su sintaxis es:
pg_dumpall > archivo_salida
y para realizar la restauración (utilizar el comando unix)
psql -f archivo_entrada postgres
Que trabaja emitiendo las consultas y comandos para recrear roles, tablespaces y Bases de Datos vacíos. Posteriormente se invoca pg_dump por cada BD para corroborar consistencia interna.
Advertencia: Es posible que el servidor dedicado no le permita restaurar, si se utiliza con el usuario postgres. Por favor, utilice este comando sólo de manera local. Pruebe utilizando su propio usuario.
Respaldo a nivel de archivos
Otra forma de realizar respaldos es a través del manejo directo de archivos, en lugar de las sentencias utilizadas.
No obstante, existen 2 restricciones que hacen que este método sea menos práctico que utilizar pg_dump:
El servidor debe ser apagado para poder obtener un respaldo utilizable.
Cada vez que se realice un respaldo, el servidor debe estar apagado, para que los cambios se guarden en su totalidad.
Advertencia: La mayor parte de las veces, se necesita acceso root, para poder realizar este tipo de operación, pues es necesario configurar archivos de configuración de postgres. Es de suma importancia que se realicen de forma correcta, pues ante algún fallo es posible destruir la base de datos de forma completa. Por lo tanto, no se abordará de forma extensa este apartado. No obstante es posible obtener información en internet.
Rsync.
Rsync corresponde a un programa que sincroniza dos directorios a través de distintos sistemas de archivos, incluso si están en distinto computadores, físicamente hablando. A través del uso de SSH o Secure SHell por sus siglas en inglés, se pueden realizar transferencias seguras y basadas en llaves de autenticación.
La principal ventaja de utilizar Rsync a diferencia de otros comandos similares, como scp, es que si el archivo que se encuentra en la fuente, es el mismo que, el que se encuentra en el objetivo, no hay transmisión de datos; si el archivo que se encuentra en el objetivo difiere del que se encuentra en la fuente, sólo aquellas partes que difieren son transmitidas, en lugar de transmitir todo, por lo que el downtime de la BD, es decir, el tiempo que debe permanecer apagada, es mucho menor.
5.1.4.2 Aplicación de Cada Método
Ejemplo de recuperación de aires.
En la fase REHACER, empezando desde el mínimo NSD en la tabla de páginas sucias(min(NSD)=1)) se rehacen las actualizaciones del log (en este caso NSD=1, 2, 6). En la fase DESHACER, se deshacen las actualizaciones del log de las transacciones no confirmadas (T3) (i.e.NSD=6).
Recuperación postgresql
Recuperación basada en WAL (Write – AheadLogging) con fases de Rehacer y Deshacer similares a Aries.
El directorio pg_xlog contiene los diarios de escritura adelantada (WAL).
Un archivo pg_clog registra el estado actual de cada transacción.
Recuperación Física: La utilización de una copia de backup de ficheros de datos siempre necesita de una recuperación física. También es así cuando un fichero de datos se pone offline sin un checkpoint.
Oracle detecta que se necesita una recuperación física cuando el contador de checkpoints de la cabecera del fichero de datos no coincide con el correspondiente contador de checkpoints del fichero de control. Entonces se hace necesario el comando recover. La recuperación comienza en el SCN menor de los ficheros de datos en recuperación, aplicando los registros de redo log a partir de él, y parando en el SCN de final mayor de todos los ficheros de datos.
Existen tres opciones para realizar una recuperacion física. La primera es una recuperación de BD donde se restaura la BD entera. La segunda es una recuperación de tablespace donde, mientras una parte de la BD está abierta, se puede recuperar un tablespace determinado. Esto significa que serán recuperados todos los ficheros de datos asociados al tablespace. El tercer tipo es la recuperación de un fichero de datos específico mientras el resto de la BD está abierta.
Requisitos para Utilizar Recuperación Física
La primera condición que se ha de poner para poder recuperar físicamente una BD es que ésta se esté utilizando en modo ARCHIVELOG. De otro modo, una recuperación completa puede que no sea posible. Si trabajamos con la BD en modo NOARCHIVELOG, y se hace una copia semanal de los ficheros de la BD, se debería estar preparado para perder, en el peor de los casos, el trabajo de la última semana si sucede un fallo. Ya que los ficheros de redo log contendrían un agujero y no se podia avanzar la BD hasta el intante anterior al fallo. En este caso el único medio para reconstruir la BD es hacerlo desde un export completo, recreando el esquema de la BD e importando todos los datos.
Recuperación de la Base de Datos
La BD debe estar montada pero no abierta. El comando de recuperación es el siguiente:
RECOVER [AUTOMATIC] [FROM 'localizacion'] [BD]
[UNTIL CANCEL]
[UNTIL TIME fecha]
[UNTIL CHANGE entero]
[USING BACKUP CONTROLFILE]
Las opciones entre corchetes son opcionales:
AUTOMATIC hace que la recuperación se haga automáticamente sin preguntar al DBA por el nombre de los ficheros redo log. También se puede utilizar para este cometido el comando set autorecovery on/off. Los ficheros redo log deben estar en la localización fijada en LOG_ARCHIVE_DEST y el formato del nombre de los ficheros debe ser el fijado en LOG_ARCHIVE_FORMAT.
FROM se utiliza para determinar el lugar donde están los ficheros redo log, si es distinto del fijado en LOG_ARCHIVE_DEST.
UNTIL sirve para indicar que se desea realizar una recuperación incompleta, lo que implica perder datos. Solo se dará cuando se han perdido redo log archivados o el fichero de control. Cuando se ha realizado una recuperación incompleta la BD debe ser abierta con el comando alter database open resetlogs, lo que produce que los redo log no aplicados no se apliquen nunca y se inicialice la secuencia de redo log en el fichero de control. Existen tres opciones para parar la recuperación:
UNTIL CANCEL permite recuperar un redo log cada vez, parando cuando se teclea CANCEL.
UNTIL TIME permite recuperar hasta un instante dado dentro de un fichero de redo log
UNTIL CHANGE permite recuperar hasta un SCN dado.
USING BACKUP CONTROLFILE utiliza una copia de seguridad del fichero de control para gobernar la recuperación.
Recuperación de un Tablespace
La BD debe estar abierta, pero con el tablespace a recuperar offline. El comando de recuperación es el siguiente:
RECOVER [AUTOMATIC] [FROM 'localizacion']
TABLESPACE nombre_tablespace [, nombre_tablespace]
Recuperación de un Fichero de Datos
La BD debe estar abierta o cerrada, dependiendo del fichero a recuperar. Si el fichero a recuperar es de un tablespace de usuario la BD puede estar abierta, pero con el fichero a recuperar offline. Si el fichero es del tablespace SYSTEM la BD debe estar cerrada, ya que no puede estar abierta con los ficheros del SYSTEM offline. El comando de recuperación es el siguiente:
RECOVER [AUTOMATIC] [FROM 'localizacion']
DATAFILE nombre_fichero [, nombre_fichero]
Creando un Fichero de Control
Si el fichero de control ha resultado dañado y se ha perdido se puede utilizar una copia de seguridad del mismo o crear uno nuevo. El comando de creación de un nuevo fichero de control es CREATE CONTROLFILE. Este comando se puede ejecutar sólo con la BD en estado nomount. La ejecución del comando produce un nuevo fichero de control y el montaje automático de la BD.
Un comando interesante que ayuda a mantener los ficheros de control a salvo es el siguiente:
SVRMGR> alter database backup controlfile to trace;
que produce un script que puede ser utilizado para generar un nuevo fichero de control y recuperar la BD, en caso necesario. El fichero de traza generado es el siguiente:
Dump file /opt/app/oracle/admin/demo/udump/demo_ora_515.trc
Oracle7 Server Release 7.3.2.3.0 - Production Release
With the distributed, replication and Spatial Data options
PL/SQL Release 2.3.2.3.0 - Production
ORACLE_HOME = /opt/app/oracle/product/7.3.2
System name: SunOS
Node name: cartan
Release: 5.5
Version: Generic
Machine: sun4m
Instance name: demo
Redo thread mounted by this instance: 1
Oracle process number: 7
Unix process pid: 515, image: oracledemo
Fri May 15 11:41:19 1998
Fri May 15 11:41:19 1998
*** SESSION ID:(6.2035) 1998.05.15.11.41.19.000
# The following commands will create a new control file and use it
# to open the database.
# No data other than log history will be lost. Additional logs may
# be required for media recovery of offline data files. Use this
# only if the current version of all online logs are available.
STARTUP NOMOUNT
CREATE CONTROLFILE REUSE DATABASE "DEMO" NORESETLOGS NOARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 2
MAXDATAFILES 30
MAXINSTANCES 1
MAXLOGHISTORY 100
LOGFILE
GROUP 1 '/export/home/oradata/demo/redodemo01.log' SIZE 2M,
GROUP 2 '/export/home/oradata/demo/redodemo02.log' SIZE 2M,
GROUP 3 '/export/home/oradata/demo/redodemo03.log' SIZE 2M
DATAFILE
'/export/home/oradata/demo/system01.dbf',
'/export/home/oradata/demo/rbs01.dbf',
'/export/home/oradata/demo/rbs02.dbf',
'/export/home/oradata/demo/rbs03.dbf',
'/export/home/oradata/demo/temp01.dbf',
'/export/home/oradata/demo/tools01.dbf',
'/export/home/oradata/demo/users01.dbf'
;
# Recovery is required if any of the datafiles are restored backups,
# or if the last shutdown was not normal or immediate.
RECOVER DATABASE
# Database can now be opened normally.
ALTER DATABASE OPEN;
Recuperación Lógica: Oracle dispone de la herramienta import para restaurar los datos de una BD a partir de los ficheros resultados de un export. Import lee los datos de los ficheros de exportación y ejecuta las sentencias que almacenan creando las tablas y llenándolas de datos.
Parámetros del Import
Parámetro
|
Defecto
|
Descripción
|
USERID
|
indefinido
|
el username/password del usuario que efectua el import.
|
BUFFER
|
dependiente del SO
|
El tamaño en bytes del buffer utilizado.
|
FILE
|
expdat.dmp
|
el nombre del fichero de exportación a importar.
|
SHOW
|
No
|
indica si se muestran los contenidos del fichero de exportación, sin importar ningún dato.
|
IGNORE
|
Yes
|
indica si ignorar los errores producidos al importar un objeto que ya existe en la BD.
|
GRANTS
|
Yes
|
indica si se importan también los derechos.
|
INDEXES
|
Yes
|
indica si se importan también los índices.
|
ROWS
|
Yes
|
indica si se importan también las filas de las tablas.
|
FULL
|
No
|
indica si se importan el fichero entero.
|
FROMUSER
|
Indefinido
|
una lista de los usuarios cuyos objetos se han exportado.
|
TOUSER
|
Indefinido
|
una lista de los usuarios a cuyo nombre se importan los objetos.
|
TABLES
|
indefinido
|
la lista de tablas a importar.
|
RECORDLENGTH
|
dependiente del SO
|
la longitud en bytes del registro del fichero.
|
INCTYPE
|
indefinido
|
el tipo de import incremental (SYSTEM o RESTORE).
|
COMMIT
|
No
|
indica si se efectua un commit después de importar cada fila. Por defecto, import efectua un commit después de cargar cada tabla.
|
PARFILE
|
indefinido
|
el fichero de parámetros.
|
Para importar un export incremental se puede efectuar la siguiente secuencia de pasos:
Utilizar la copia más reciente del import para restaurar las definiciones del sistema:
$ imp userid=sys/passwd inctype=system full=Y file=export_filename
Poner los segmentos de rollback online.
Importar el fichero de exportación completa más reciente:
$ imp userid=sys/passwd inctype=restore full=Y file=filename
Importar los ficheros de exportación en modo acumulación desde la exportación completa más reciente, en orden cronológico:
$ imp userid=sys/passwd inctype=restore full=Y file=filename
Importar los ficheros de exportación en modo incremental desde la exportación completa o acumulativa más reciente, en orden cronológico:
$ imp userid=sys/passwd inctype=restore full=Y file=filename
5.2 Migración de la Base de Datos.
Los conceptos esenciales de la migración describen cambios realizados en el soporte para el desarrollo de aplicaciones, cambios el soporte de nuevas funciones, funciones no soportadas y funciones en desuso que pueden afectar a las aplicaciones de base de datos, scripts y herramientas.
Migración de aplicaciones de BD dentro de DB2
Cambios en el soporte de los sistemas operativos
Cambios en los controladores de las aplicaciones
Cambios en el soporte del software de desarrollo
Cambios en las API de DB2 y en los mandatos de DB2
Cambios en la sintaxis de las sentencias de SQL
Cambios en las vistas y rutinas administrativas de SQL y en las vistas de catálogo
Paquetes de base de datos
Cambios en el soporte de 32 bits y 64 bits
Cambios en el comportamiento del servidor DB2
Soporte de conectividad de clientes DB2
En este caso, los datos, que estarán en formato "access" deberán pasar a formato "sqlserver" o formato para "oracle". La migración de los datos consiste en convertir los datos desde un sistema de base de datos a otro. Esta migración conlleva la creación de tablas o modificación de las existentes, cambios en algunos tipos de datos que existen en una base de datos pero no en otras, etc.
Especialmente delicados son los campos fecha, los numéricos (enteros, reales, etc), los de tipo "memo" o campos de extensión superior a 256 caracteres, campos para imágenes, etc, ya que cada SGBD los trata o los "espera" de manera diferente.
Actualmente la mayoría de SGBD incluyen herramientas de ayuda a la migración más o menos "fiables". No obstante, ni que decir tiene que el proceso de migración de datos es lo suficientemente delicado como para realizarlo en un entorno de pruebas, contemplando toda la casuística posible en cuanto a tipos de datos a manejar, tablas involucradas y sus relaciones, etc.
Sólo en el momento en el que estemos seguros de que la migración se ha realizado con éxito, sin problemas de interpretación de datos ni pérdida de ellos, podemos pasar a un entorno de producción. Teniendo en cuenta que una migración mal realizada podría dar por terminada una estructura de información completa.
Técnicas de Migración de Datos.
Planeación: Lo más importante al migrar una Base de Datos es llevar a cabo un proceso de planeación y análisis del trabajo, puesto que aunque pareciera tomarse algún tiempo adicional, éste será retribuido en el éxito de la operación y menos costos por errores de datos. Es importante que esto sea aplicado cuando la Base de Datos destino está en producción.
Contador de Registros.
Si la migración se realiza de forma manual, mediante alguna consulta de inserción es recomendable inicializar un contador para cada registro insertado con éxito y otro para los no insertados, así obviamente, la suma de ambos debe ser igual a los registros originales.
Mapeador de Tipo de Datos
Algunas plataformas no soportan algunos tipos de datos, así que es necesario planificar el mapeo de los campos en la nueva base de datos.
Restricciones y Trigers.
Antes de iniciar la migración de la BD, es recomendable deshabilitar los Trigers y/o restricciones que nos puedan generar error al momento que el DBMS ejecute el proceso de escritura de los datos.
Codificación de Caracteres
Cuando el copiado se realiza de forma automática, es necesario identificar la codificación de caracteres que la BD destino espera, pues así evitaremos el reemplazo automático de caracteres o en su caso, pérdida de los mismos
Factor crítico para el éxito de la migración de la base de datos es la realización de pruebas para validar o modificar la arquitectura final y el plan de migración, así como para comprobar que las aplicaciones funcionan correctamente.
Actualmente la información se ha convertido en un activo importante para las organizaciones tanto públicas como privadas; dicha información se obtiene mediante la extracción e interpretación de los datos que posee la organización, algunos de los cuales se encuentran almacenados en sus bases de datos (BD).
Una base de datos en su concepto más simple, se refiere a un conjunto de datos relacionados entre sí con un objetivo común. De acuerdo con C. J. Date, en su libro Introducción a las bases de datos: “es una colección de datos integrados, con redundancia controlada y con una estructura que refleje las interrelaciones y restricciones existentes en el mundo real; los datos que han de ser compartidos por diferentes usuarios y aplicaciones, deben mantenerse independientes de éstas, y su definición y descripción, únicas para cada tipo de dato, han de estar almacenadas junto con los mismos. Los procedimientos de actualización y recuperación, comunes, y bien determinados, habrán de ser capaces de conservar la integridad, seguridad y confidencialidad del conjunto de datos”.
En tanto que una migración de BD es un proceso que se realiza para mover o trasladar los datos almacenados en un origen de datos a otro, para lo cual es indispensable que antes de empezar cualquier proceso de esta naturaleza, se tenga clara y documentada la razón por la cual se está migrando, además de elaborarse la planeación detallada de las actividades contempladas. Dicha migración se requiere llevar a cabo cuando es necesario mover un esquema dentro del mismo servidor, o de un servidor a otro, así como para actualizar la versión del software, y hacer un cambio de manejador de bases de datos por el de otro fabricante o para cambiarlo a una plataforma de cómputo distinta.
Existen diversos motivos para hacer una migración, tales como: mejorar el desempeño de la base de datos, cumplir con nuevos requerimientos de usuario, de la aplicación o políticas de seguridad; así como la compatibilidad con otras aplicaciones, la actualización de versiones, la estandarización de la tecnología de información en la organización, la reducción de costos que se puede tener al cambiar por software libre, el aumento en el volumen de datos, nuevos procesos de negocio, entre otros escenarios posibles.
Es conveniente hacer notar que en la planeación del proyecto de migración, se debe delimitar el alcance, definir la estrategia por seguir, identificar en forma completa los requerimientos, hacer un análisis de riesgos, así como analizar las condiciones actuales y finales. En esta fase es necesario, igualmente, determinar la viabilidad técnica y la factibilidad económica de la solución planteada; pero antes, es oportuno realizar respaldos de la base de datos antes y después del proceso de migración, así como considerar en qué momento y durante cuánto tiempo se va a detener la operación de la base de datos en producción. Si esto no es posible, se debe determinar el procedimiento para identificar los datos que fueron ingresados durante el proceso de migración, para su actualización posterior.
Durante la migración, propiamente, se realizan procesos de extracción, transformación y carga, los cuales incluyen el obtener los datos desde su origen, modificarlos para cumplir con la integridad, la consistencia y las reglas del negocio definidas para, finalmente insertarlos en la base de datos destino. Una actividad central del proceso es realizar un análisis del modelo de datos actual y del nuevo, para determinar cuáles son las tablas y campos críticos de ambos; posteriormente, se analizará y documentará la correspondencia campo por campo del nuevo modelo con el modelo actual, especificando los valores por defecto, nulos, la tabla o tablas que serán el origen de datos de cada relación en el nuevo modelo y las dependencias funcionales de cada una de ellas.
Adicionalmente, se debe contemplar la verificación de la integridad referencial entre las tablas de acuerdo con los requerimientos del modelo en el nuevo ambiente y determinar las limitaciones existentes. De esta manera, es necesario considerar las diferencias de los tipos de datos entre el modelo actual y el nuevo, asegurar que la información pueda ser almacenada en los campos bajo la nueva definición, verificar el tamaño de los objetos y de la base de datos, revisar el tipo de índices que soporta la base de datos final y su manejo de transacciones.
Por otro lado, si el alcance del proyecto incluye la migración de procedimientos almacenados, cuando hay un cambio de manejador de bases de datos (RDBMS), se debe considerar que tal vez sea necesario programarlos nuevamente, en tantoel código puede no ser compatible. También se recomienda probar de manera exhaustiva, que las consultas realizadas por las aplicaciones, puedan seguir ejecutándose normalmente. Esta actividad es una parte fundamental del proceso, debido a que los datos almacenados se vuelven importantes conforme pueden ser convertidos en información valiosa para los usuarios.
Existen otros aspectos que se deben tener en cuenta para el éxito del proyecto, tales como: contar con el apoyo de la alta dirección, asignar a un equipo con la experiencia y competencias requeridas, identificar las aplicaciones críticas que harán uso de los datos, la disponibilidad requerida de la BD, así como contar con los recursos e infraestructura necesarios bajo el dimensionamiento realizado.
Factor crítico para el éxito de la migración de la base de datos es la realización de pruebas las cuales, inicialmente, pueden ser a pequeña escala para validar o modificar la arquitectura final y el plan de migración, así como para comprobar que las aplicaciones que harán uso de la base de datos funcionan correctamente y optimizar los tiempos y recursos necesarios. Es recomendable hacer pruebas generales para comprobar que el proceso completo funciona correctamente, medir los tiempos para tener una planeación integral y minimizar los riesgos.
Una vez terminado el proceso se deben medir los resultados y entregar un reporte global del trabajo realizado, mencionando cuáles son los productos que se entregan, cuántas tablas u otros objetos fueron migrados, cuántos registros se migraron exitosamente, cuántos no fueron migrados y cuál fue la causa de ello.
Se sugiere realizar el reporte ejecutivo que resuma y presente a los directivos, los resultados obtenidos. Otro documento relevante para el cliente es la memoria técnica que contenga la configuración de los parámetros de la base de datos migrada, su estructura física y espacio disponible, entre otros datos relevantes.
La migración de datos, por sí misma, puede ser considerada como un proyecto complejo que para ser exitoso requiere una planeación detallada, un profundo conocimiento tanto de los datos como de las herramientas necesarias para llevar a cabo el proceso, así como en forma importante, de los sistemas y aplicaciones que hacen uso de los datos a partir del modelo final, para asegurar su correcto funcionamiento y continuidad en la operación.
Indicaciones útiles para migrar una base de datos a MySQL, es decir, cuando tenemos que subir una base de datos local en cualquier gestor a una base de datos remota en MySQL. El último caso en el que nos podemos encontrar a la hora de subir una base de datos a nuestro proveedor de alojamiento es que la base de datos la tengamos creada en local, pero en un sistema gestor distinto del que vamos a utilizar en remoto. En remoto suponemos siempre que vamos a utilizar la base de datos MySQL. En local podríamos disponer de una base de datos Access, SQL Server o de otro sistema de base de datos.
El proceso de la migración puede ser bastante complejo y, como hay tantas bases de datos distintas, difícil de dar una receta que funcione en todos los casos. Además, aparte de la dificultad de transferir la información entre los dos sistemas gestores de base de datos, también nos influirá mucho en la complejidad del problema el tipo de los datos de las tablas que estamos utilizando. Por ejemplo, las fechas, los campos numéricos con decimales o los boleanos pueden dar problemas al pasar de un sistema a otro porque pueden almacenarse de maneras distintas o, en el caso de los números, con una precisión distinta.
Recomendaciones Para Migrar de Access a MySQL.
Este tema está relatado en el artículo Exportar datos de MySQL a Access, aunque hay que indicar que si deseamos hacer una exportación desde Access en local a MySQL en remoto puede haber problemas porque no todos los alojadores permiten las conexiones en remoto con la base de datos. Si no tenemos disponible una conexión en remoto con nuestro servidor de bases de datos vamos a tener que cambiar la estrategia un poco.
Recomendaciones Para Migrar Desde SQL Server a MySQL.
La verdad es que no he tenido este caso nunca, pero hay que decir que Access también nos puede ayudar en este caso. Access permite seleccionar una base de datos SQL Server y trabajar desde la propia interfaz de Access. La idea es que Access también permite trabajar con MySQL y posiblemente haciendo un puente entre estos dos sistemas gestores podemos exportar datos de SQL Server a MySQL.
Lo que es seguro que utilizando el propio Access de puente podríamos realizar el trabajo. Primero exportando de SQL Server a Acess y luego desde Access a MySQL.
Otras Bases de Datos u Otras Técnicas.
Si la base de datos origen dispone de un driver ODBC no habrá (en teoría) problema para conectarla con Access, de manera similar a como se conecta con MySQL. Entonces podríamos utilizar Access para exportar los datos, porque desde allí se podrían acceder a los dos sistemas gestores de bases de datos.
Si no tenemos Access, o la base de datos original no tiene driver ODBC, o bien no nos funciona correctamente el proceso y no sabemos cómo arreglarlo, otra posibilidad es exportar los datos a ficheros de texto, separados por comas o algo parecido. Muchas bases de datos tienen herramientas para exportar los datos de las tablas a ficheros de texto, los cuales se pueden luego introducir en nuestro sistema gestor destino (MySQL) con la ayuda de alguna herramienta como PhpMyAdmin.
Para ello, en la página de propiedades de la tabla encontraremos una opción para hacer el backup de la tabla y para introducir ficheros de texto dentro de una tabla (Insert textfiles into table en inglés).
Accediendo a ese enlace podremos ver un formulario donde introducir las características del fichero de texto, como el carácter utilizado como separador de campos, o el terminador de líneas, etc, junto con el propio archivo con los datos, y PhpMyAdmin se encargará de todo el trabajo de incluir esos datos en la tabla.
Como se habrá supuesto, es necesario tener creada la tabla en remoto para que podamos introducirle los datos del fichero de texto.
Cambios de un Formato de Datos a Otro
Toda la migración tiene que tener en cuenta muy especialmente, como ya se señaló, las maneras que tenga cada base de datos de guardar la información, es decir, del formato de sus tipos de datos. Tenemos que contar siempre con la posible necesidad de transformar algunos datos como pueden ser los campos boleanos, fechas, campos memo (texto con longitud indeterminada), etc, que pueden almacenarse de maneras distintas en cada uno de los sistemas gestores, origen y destino.
En algunos casos posiblemente tengamos que realizar algún script que realice los cambios necesarios en los datos. Por ejemplo puede ser para localizar los valores boleanos guardados como true / false a valores enteros 0 / 1, que es como se guarda en MySQL. También las fechas pueden sufrir cambios de formato, mientras que en Access aparecen en castellano (dd/mm/aaaa) en MySQL aparecen en el formato aaaa-mm-dd. PHP puede ayudarnos en la tarea de hacer este script, también Visual Basic Script para Access puede hacer estas tareas complejas y el propio lenguaje SQL, a base de sentencias dirigidas contra la base de datos, puede servir para algunas acciones sencillas.
5.3 Monitoreo y Auditoría de la Base de Datos.
La auditoría y la protección de bases de datos (DAP) representa un avance evolutivo importante con respecto a anteriores herramientas de monitoreo de actividad en bases de datos (DAM). Los gerentes de seguridad, los administradores de bases de datos (DBAs) y otros interesados, que estén preocupados con proteger datos sensibles en las bases de datos, deben evaluar estas herramientas.
¿Qué es la Auditoría de BD?
Es el proceso que permite medir, asegurar, demostrar, monitorear y registrar los accesos a la información almacenada en las bases de datos incluyendo la capacidad de determinar:
Quién accede a los datos.
Cuándo se accedió a los datos.
Desde qué tipo de dispositivo/aplicación.
Desde que ubicación en la Red.
Cuál fue la sentencia SQL ejecutada.
Cuál fue el efecto del acceso a la base de datos.
Es uno de los procesos fundamentales para apoyar la responsabilidad delegada a IT por la organización frente a las regulaciones y su entorno de negocios o actividad.
Objetivos Generales de la Auditoría de Base de Datos.
Disponer de mecanismos que permitan tener trazas de auditoría completas y automáticas relacionadas con el acceso a las bases de datos incluyendo la capacidad de generar alertas con el objetivo de:
Mitigar los riesgos asociados con el manejo inadecuado de los datos.
Apoyar el cumplimiento regulatorio.
Satisfacer los requerimientos de los auditores.
Evitar acciones criminales.
Evitar multas por incumplimiento.
La importancia de la auditoría del entorno de bases de datos radica en que es el punto de partida para poder realizar la auditoría de las aplicaciones que utiliza esta tecnología.
La Auditoría de Base de Datos es importante Porque:
Toda la información financiera de la organización reside en bases de datos y deben existir controles relacionados con el acceso a las mismas.
Se debe poder demostrar la integridad de la información almacenada en las bases de datos.
Las organizaciones deben mitigar los riesgos asociados a la pérdida de datos y a la fuga de información.
La información confidencial de los clientes, son responsabilidad de las organizaciones.
Los datos convertidos en información a través de bases de datos y procesos de negocios representan el negocio.
Las organizaciones deben tomar medidas mucho más allá de asegurar sus datos.
5.3.1 Monitoreo
El término Monitoreo es un término no incluido en el diccionario de la Real Academia Española (RAE). Su origen se encuentra en monitor, que es un aparato que toma imágenes de instalaciones filmadoras o sensores y que permite visualizar algo en una pantalla. El monitor, por lo tanto, ayuda a controlar o supervisar una situación.
Esto nos permite inferir que monitoreo es la acción y efecto de monitorear, el verbo que se utiliza para nombrar a la supervisión o el control a través de un monitor. Por extensión, el monitoreo es cualquier acción de este tipo, más allá de la utilización de un monitor.
5.3.1.1 Monitoreo General de un DBMS.
DAP— un término que Gartner desarrolló para remplazar el anterior concepto de DAM —se refiere a las suites de herramientas que se utilizan para apoyar la identificación y reportar comportamiento inapropiado, ilegal o de otra forma indeseable en las RDBMSs, con mínimo impacto en las operaciones y la productividad del usuario. Estas suites han evolucionado de herramientas DAM, que ofrecían análisis de la actividad del usuario en las RDBMSs y alrededor de ellas, para abarcar un conjunto más integral de capacidades, que incluyen:
Descubrimiento y clasificación.
Gestión de vulnerabilidades.
Análisis al nivel de aplicación.
Prevención de intrusión.
Soporte de seguridad de datos no estructurados.
Integración de gestión de identidad y acceso.
Soporte de gestión de riesgos.
5.3.1.2 Monitoreo de Espacio en Disco.
El Espacio en Disco.
El abaratamiento de los discos ha reducido considerablemente la incidencia del espacio ocupado por los usuarios. No obstante, los discos requieren administración: hay que instalarlos, darles formato, montarlos en otras máquinas, respaldarlos, monitorearlos. Aunque el espacio en disco sea suficiente, es preciso insistir ante los usuarios para hacer un uso racional del recurso.
Comandos para el monitoreo del espacio en disco
quot
du
El comando
du
da un resumen del uso de disco en una rama de directorios.
du -s /export/home/*
Muestra el total para cada rama de subdirectorio bajo /export/home;
Esto no es efectivo para ver el consumo total de cada usuario si los usuarios tienen archivos en otras partes del sistema.
df
El comando
df
da un resumen del uso del espacio a nivel de todo el sistema:
df
Muestra el espacio utilizado en cada sistema de archivos, incluso a veces en los que están montados vía NFS. Si se indica uno en particular, da el espacio utilizado en ese sistema de archivos:
df /dev/hda2.
El comando
quot
informa sobre el espacio en disco consumido por los usuarios en cada sistema de archivos:
quot -f /dev/hda2
Proporciona una lista de la cantidad de bloques y archivos a nombre de cada usuario.
5.3.1.3 Monitoreo de Logs.
Monitorear el log de transacciones es una de las actividades más importantes para los administradores de bases de datos, ya que en caso de que este llegara a llenarse, no podrían llevarse a cabo más transacciones sobre esta base de datos quedando fuera de servicio.
Monitoreando el Log de Transacciones(SQL SERVER)
Monitorear el log regularmente puede ayudarnos a resolver varios problemas dentro de nuestros sistemas, ya que este puede indicarnos si existen demasiadas transacciones realizadas por una sola aplicación, que podría resultar en un mal diseño o simplemente la necesidad de planear mejor los recursos de log en nuestro servidor de base de datos.
Monitoreo de Logs
Una de ellas es mediante un comando desde el analizador de consultas:
Desde el analizador de consultas ejecutar el comando DBCC SQLPERF(LOGSPACE).
Monitoreo de Logs
La otra utilizando los contadores de SQL Server desde el sistema operativo.
Monitoreo de Log transacciones
5.3.1.4 Monitoreo de Memoria compartida
5.3.1.5 Monitoreo de Base de Datos
5.3.1.6 Monitoreo de modos de operación.
5.3.1.7 Monitoreo de espacios espejeados.
5.3.2 Auditoría
5.3.2.1 Habilitación y deshabilitar el modo de auditoría
5.3.2.2 Consultas de las tablas vistas con información de la auditoría
5.4 Herramientas de software y hardware para monitoreo y administración automática


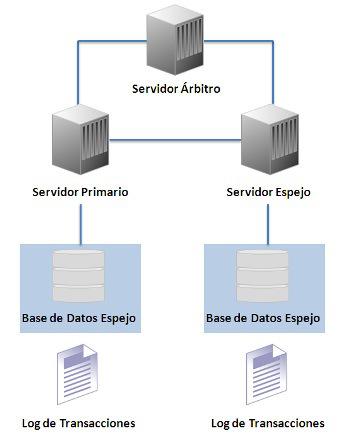
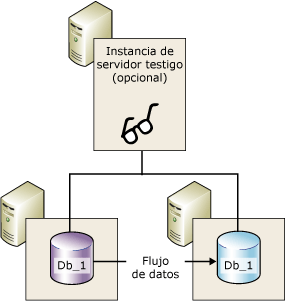
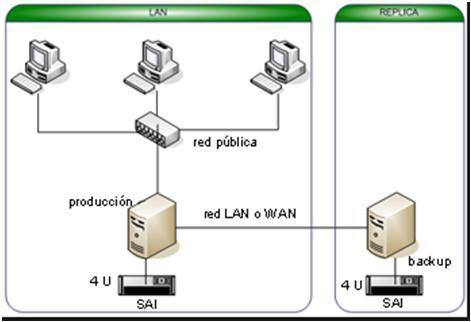
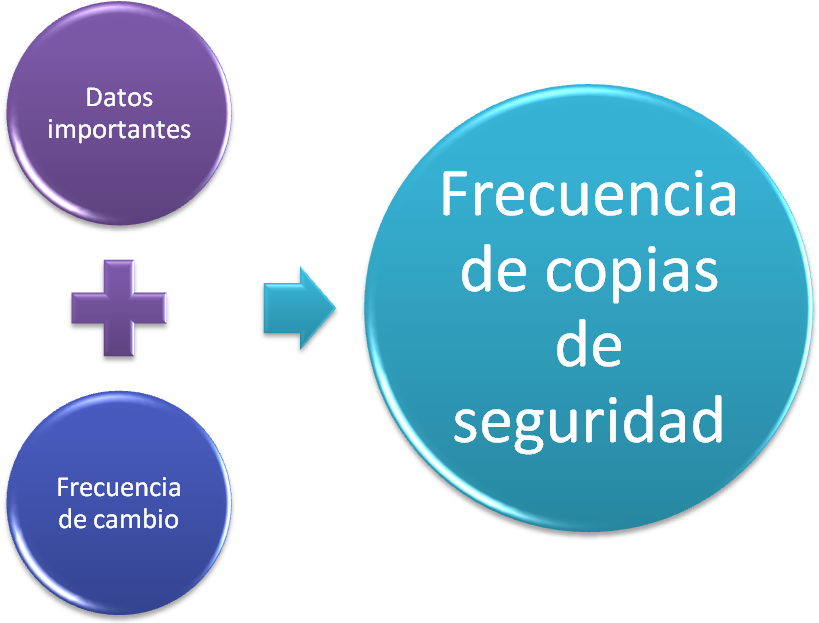

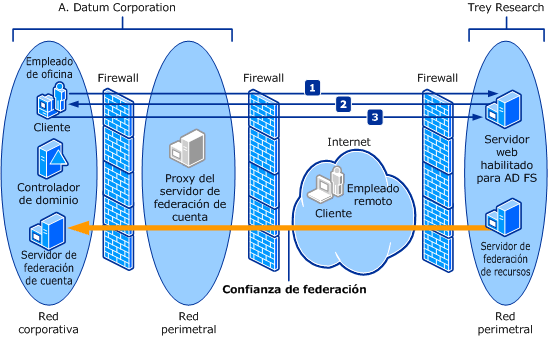



{kind=link}